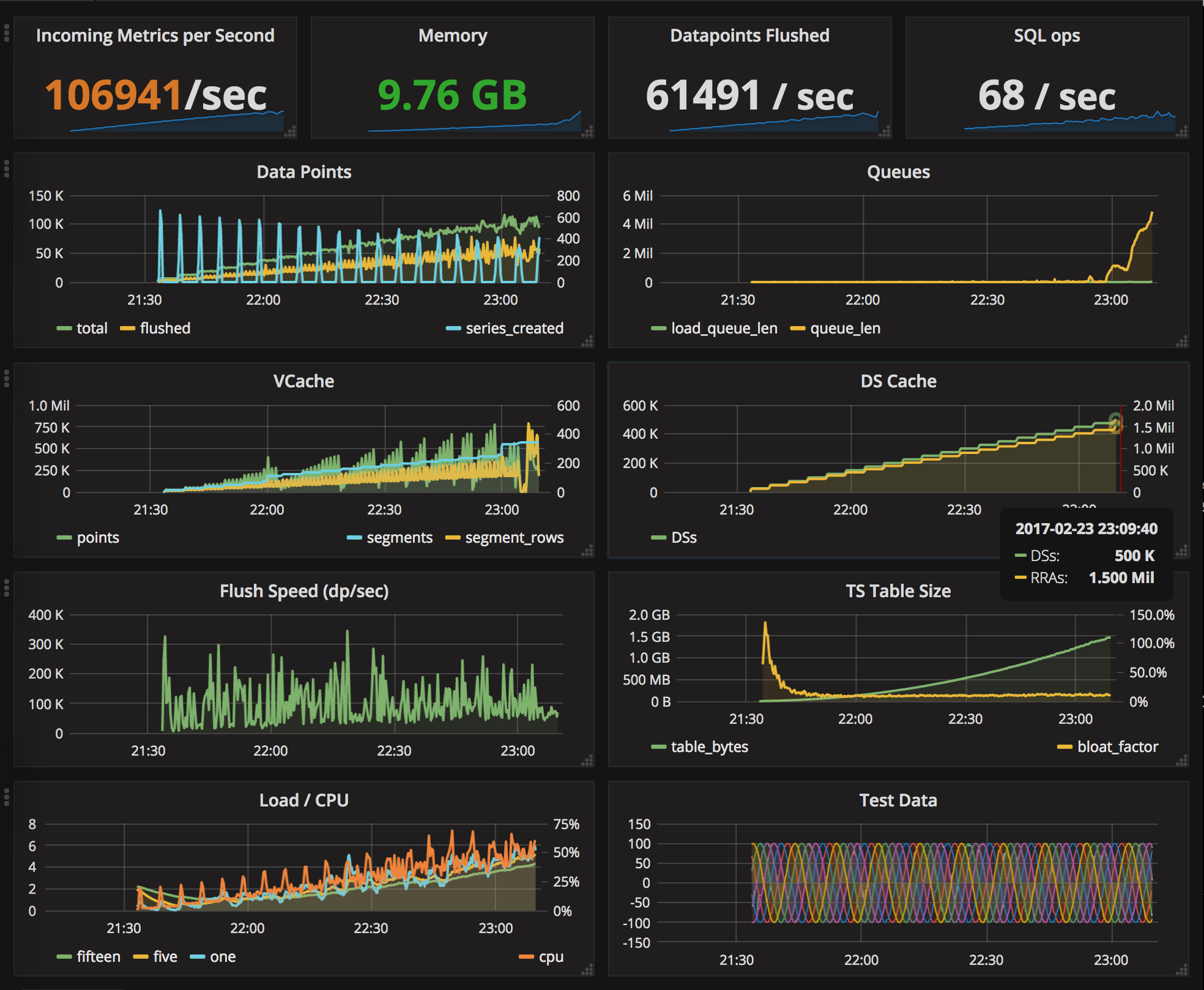
This is part 3. See part 1 and part 2.
The previous two posts got us to a point where we had a Go app which was able to serve a tiny bit of HTML. This post will talk about the client side, which, alas, is mostly JavaScript, not Go.
JavaScript in 2017
This is what gave me the most grief. I don’t really know how to categorize the mess that present day JavaScript is, nor do I really know what to attribute it to, and trying to rationalize it would make for a great, but entirely different blog post. So I’m just going to accept this as the reality we cannot change and move on to how to best work with it.
Variants of JS
The most common variant of JS these days is known as ES2015 (aka ES6 or ECMAScript 6th Edition), and it is mostly supported by the more or less latest browsers. The latest released spec of JavaScript is ES7 (aka ES2016), but since the browsers are sill catching up with ES6, it looks like ES7 is never really going to be adopted as such, because most likely the next coming ES8 which might be released in 2017 will supersede it before the browsers are ready.
Curiously, there appears to be no simple way to construct an environment fully specific to a particular ECMAScript version. There is not even a way to revert to an older fully supported version ES5 or ES4, and thus it is not really possible to test your script for compliance. The best you can do is to test it on the browsers you have access to and hope for the best.
Because of the ever changing and vastly varying support for the
language across platforms and browsers, transpilation has emerged as
a common idiom to address this. Transpilation mostly amounts to
JavaScript code being converted to JavaScript that complies with a
specific ES version or a particular environment. For example import
Bar from 'foo'; might become var Bar = require('foo');. And so if a
particular feature is not supported, it can be made available with the
help of the right plug-in or transpiler. I suspect that the
transpilation proliferation phenomenon has led to additional problems,
such as the input expected by a transpiler assuming existence of a
feature that is no longer supported, same with output. Often this
might be remedied by additional plugins, and it can be very difficult
to sort out. On more than one occasion I spent a lot of time trying to
get something to work only to find out later that my entire approach
has been obsoleted by a new and better solution now built-in to some
other tool.
JS Frameworks
There also seems to be a lot of disagreement on which JS framework is best. It is even more confusing because the same framework can be so radically different from one version to the next I wonder why they didn’t just change the name.
I have no idea which is best, and I only had the patience to try a couple. About a year ago I spent a bunch of time tinkering with AngularJS, and this time, for a change, I tinkered with React. For me, I think React makes more sense, and so this is what this example app is using, for better or worse.
React and JSX
If you don’t know what React is, here’s my (technically incorrect) explanation: it’s HTML embedded in JavaScript. We’re all so brainwashed into JavaScript being embedded in HTML as the natural order of things, that inverting this relationship does not even occur as a possibility. For the fundamental simplicity of this revolutionary (sic) concept I think React is quite brilliant.
A react “Hello World!” looks approximately like this:
1 2 3 4 5 6 7 8 | |
Notice how the HTML just begins without any escape or delimiter. Surprisingly, the opening “<” works quite reliably as the marker signifying beginning of HTML. Once inside HTML, the opening curly brace indicates that we’re back to JavaScript temporarily, and this is how variable values are interpolated inside HTML. That’s pretty much all you need to know to “get” React.
Technically, the above file format is known as JSX, while React is
the library which provides the classes used to construct React objects
such as React.Component above. JSX is transpiled into regular
JavaScript by a tool known as Babel, and in fact JSX is not even
required, a React component can be written in plain JavaScript, and
there is a school of thought whereby React is used without JSX. I
personally find the JSX-less approach a little too noisy, and I also
like that Babel allows you to use a more modern dialect of JS (though
not having to deal with a transpiler is definitely a win).
Minimal Working Example
First, we need three pieces of external JavaScript. They are (1) React
and ReactDOM, (2) Babel in-browser transpiler and (3) a little lib
called Axios which is useful for making JSON HTTP requests. I get them
out of Cloudflare CDN, there are probably other ways. To do this, we
need to augment our indexHTML variable to look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
At the very end it now loads "/js/app.jsx" which we need to
accommodate as well. Back in part 1 we created a UI config variable
called cfg.Assets using http.Dir(). We now need to wrap it in
a handler which serves files, and Go conveniently provides one:
1
| |
With the above, all the files in "assets/js" become available under
"/js/".
Finally we need to create the assets/js/app.jsx file itself:
1 2 3 4 5 6 7 8 9 10 | |
The only difference from the previous listing is the very last line, which is what makes the app actually render itself.
If we now hit the index page from a (JS-capable) browser, we should see a “Hello World”.
What happened was that the browser loaded “app.jsx” as it was instructed, but since “jsx” is not a file type it is familiar with, it simply ignored it. When Babel got its chance to run, it scanned our document for any script tags referencing “text/babel” as its type, and re-requested those pages (which makes them show up twice in developer tools, but the second request ought to served entirely from browser cache). It then transpiled it to valid JavaScript and executed it, which in turn caused React to actually render the “Hello World”.
Listing People
We need to first go back to the server side and create a URI that lists people. In order for that to happen, we need an http handler, which might look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
And we need to register it:
1
| |
Now if we hit "/people", we should get a "[]" in response. If we
insert a record into our people table with something along the lines
of:
1
| |
The response should change to [{"Id":1,"First":"John","Last":"Doe"}].
Finally we need to hook up our React/JSX code to make it all render.
For this we are going to create a PersonItem component, and
another one called PeopleList which will use PersonItem.
A PersonItem only needs to know how to render itself as a table row:
1 2 3 4 5 6 7 8 9 10 11 | |
A PeopleList is slightly more complicated:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
It has a constructor which initializes a this.state variable. It
also declared a componentDidMount() method, which React will call
when the component is about to be rendered, making it the (or one of)
correct place to fetch the data from the server. It fetches the data
via an Axios call, and saves the result in
this.state.people. Finally, render() iterates over the contents of
this.state.people creating an instance of PersonItem for each.
That’s it, our app now responds with a (rather ugly) table listing people from our database.
Conclusion
In essence, this is all you need to know to make a fully functional Web App in Go. This app has a number of shortcomings, which I will hopefully address later. For example in-browser transpilation is not ideal, though it might be fine for a low volume internal app where page load time is not important, so we might want to have a way to pre-transpile it ahead of time. Also our JSX is confined to a single file, this might get hard to manage for any serious size app where there are lots of components. The app has no navigation. There is no styling. There are probably things I’m forgetting about…
Enjoy!
P.S. Complete code is here
Continued in part 4…